



Surgeon Cognitive Dashboard: Case Study
A proof-of-concept cognitive state monitor for robotic surgery training with no wearables and real-time biosignal fusion
Human Factors
Pupillometry
XGBoost
R Shiny
ML
A proof-of-concept for a real-time analytics platform that uses pupillometry and motor-based metrics to predict a surgeon’s cognitive state, inspired by my work at Surgical Science & Technology.
RoleSole Designer & Developer: Concept, Modeling, Deployment
MethodsPupillometry, HRV, XGBoost, Platt Scaling, SDT, Bayesian Inverted-U policies
StackR, R Shiny, XGBoost, ShinyApps.io
OutputLive Shiny dashboard · Training Lab app · Case study
TL;DR
Goal: Reduce high-load minutes per hour, prevent cognitive lapses, and keep surgical trainees in the optimal arousal zone using pupillometry, grip/tremor, and HRV without any body-worn hardware.
What I built: A Training Lab for exploring and calibrating threshold policies, and a Production Dashboard that runs those policies in real time with interpretable alerts.
What I built: A Training Lab for exploring and calibrating threshold policies, and a Production Dashboard that runs those policies in real time with interpretable alerts.
Why I built this
Surgical Safety Technologies (SST) · Research Assistant / AI Annotator
- Assisted on instance segmentation pipelines for surgical tool detection and tracking
- Computed inter-rater reliability (κ/ICC) for analyst labels
- Reviewed ML-for-surgical-safety literature to support analyst operations
Takeaway: The bottleneck was never model accuracy. It was alarm fatigue and interface friction. Labels drift; adoption is decided by hygiene and UX.
UC Riverside · PhD dissertation
- Testing concurrent physical effort (5% vs 40% MVC) × cognitive load with pupillometry
- Domains: working and long-term memory, auditory and visual discrimination
- Theoretical frame: Resource Competition + Neural Gain (adaptive gain theory)
Takeaway: Pupil-indexed LC–NE activity links arousal to decision-making quality, providing a measurable, real-time signal that doesn’t require a headset.
Why this dashboard: SST showed me what breaks in the OR when monitoring goes wrong. My dissertation gave me the mechanism to do it better. This project combines the two: deployable UX discipline from SST with LC–NE–grounded signal design from the lab.
Executive Summary
Robotic surgery places sustained cognitive demand on operators for procedures that routinely exceed two hours, with no objective, real-time signal of when that demand is impairing judgment or fine motor control. The OR is tightly constrained, so the design avoids new body-worn hardware and lengthy calibration. Instead, it fuses existing robot telemetry with unobtrusive biosignals to deliver real-time coaching.
I built two tightly coupled tools:
- Training Lab: makes load/fatigue felt and lets instructors choose a threshold policy to match their pedagogy.
- Production Dashboard: runs those policies in real time using pupil + grip/tremor + HRV, tuned to prevent alarm fatigue and respect sterile-field constraints.
Model accuracy is a starting point, not the goal. I optimize for operational outcomes, including fewer high-load minutes per hour, faster post-alert recovery, and shorter time-to-proficiency, alongside standard classifier metrics.
Note
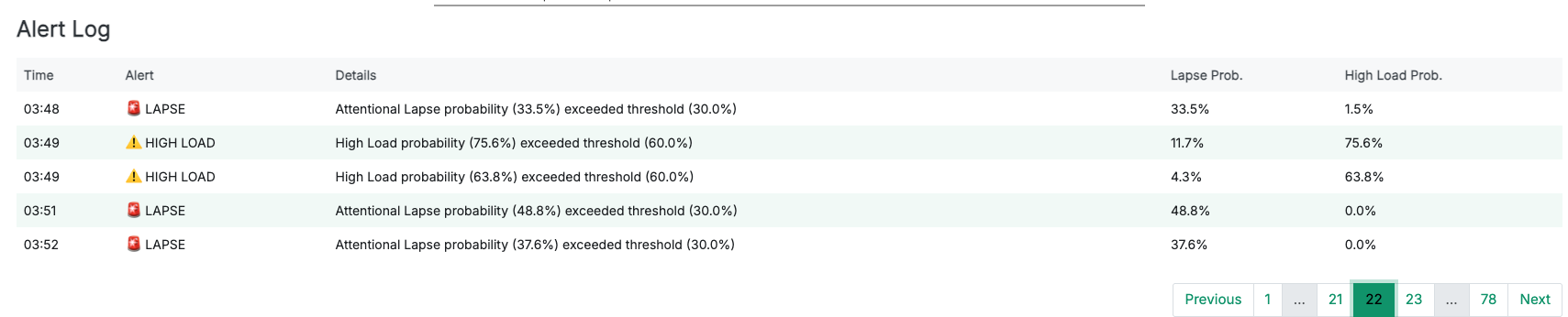
Deployment KPIs: Alert burden ≤ 0.6/min, High-Load min/hr ↓, Time-to-Recovery sec ↓, Acknowledgement rate ↑.
Surgical Cognitive Dashboard
No body-worn hardware, real-time neuro-ergonomics for robotic surgery.
Objectives: what this actually delivers
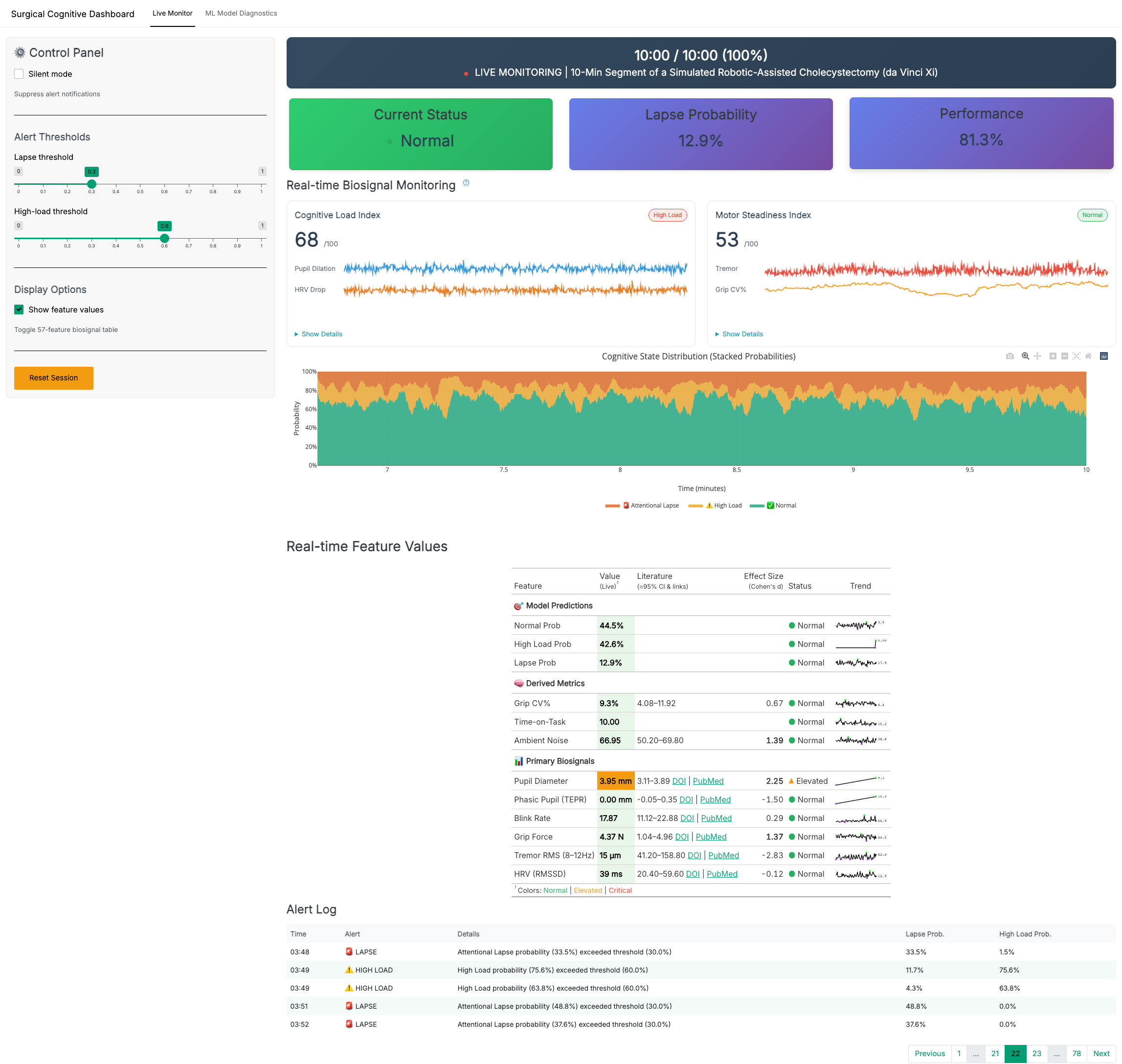
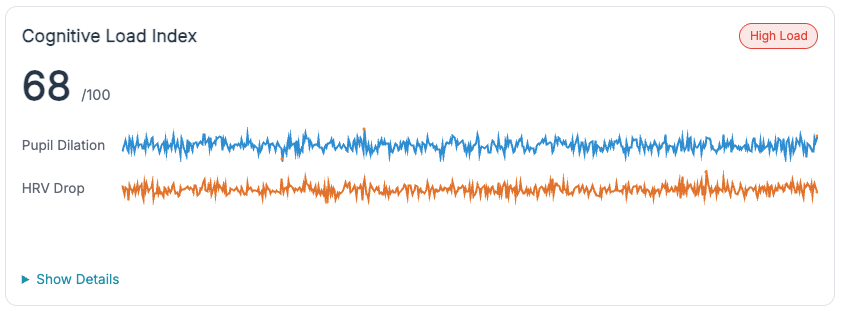
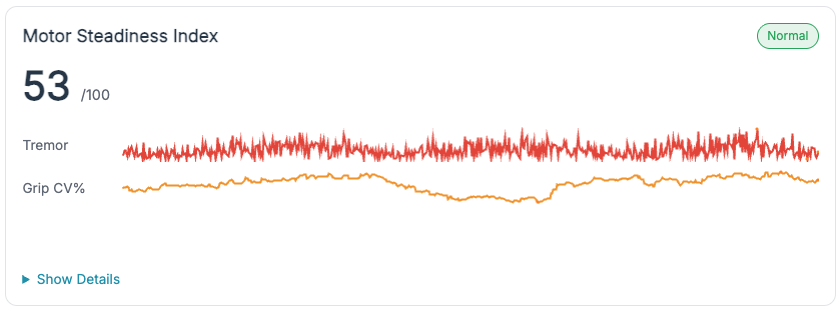
Non-intrusive signal fusion. Pupil diameter, HRV, and grip/tremor are combined with existing robot telemetry to estimate cognitive state (Normal / High-Load / Lapse) without body-worn hardware or lengthy calibration.
Training-outcome focus. The primary metrics are operational: high-load minutes per hour, time-to-recovery after microbreaks, and sessions to competency rubric, not just classifier AUC.
Three teachable threshold policies. Adaptive Gain (arousal sweet-spot), Dual-Criterion SDT (false-alarm control with hysteresis), and Time-on-Task (fatigue-adaptive relaxation). Each maps to a real instructional strategy and is adjustable at runtime.
Sterile-field compatible. Setup under 60 seconds, no new wearables, sensible defaults, and guardrails against alarm spam.
Who benefits and why
- Residents. See when trainees drift into low arousal or overload; get just-enough nudge (microbreaks, pacing, framing) without flooding them.
- Instructors. A common language for when to step in: high-load confirmed by TEPR↑ + HRV↓, lapse suggested by low TEPR + blink anomalies.
- Program directors / ops. Track high-load min/hr, recovery latency, and alarm burden across sessions to prove training impact and tune curricula.
Personalized coaching: how it adapts to the trainee
Idea. Each trainee has a different “inverted-U” width and bias. The system infers a coaching profile from early sessions:
- Wide band: tolerates more challenge before overload → allow denser feedback; push complexity sooner.
- Narrow band: tips into overload quickly → favor microbreaks, chunk tasks, reduce concurrent demands.
Heuristics (evidence-informed, lightweight):
- Likely overload (right limb):
z(TEPR) ≥ +0.8ANDRMSSD ↓ ≥ 25–35%over 60–120 s → suggest microbreak or slow tool motions for 60–120 s. - Likely lapse (left side):
z(TEPR) ≤ −0.5OR blink bursts + stable HRV → prompt re-centering (brief cueing, checklist, or instructor query). - Stable but trending: slope(High-Load prob, 90 s) > 0 with rising grip CV → anticipatory nudge (“prepare break after this step”).
Not a diagnosis. This is training feedback, not medical inference. Requires individual calibration and instructor judgment.
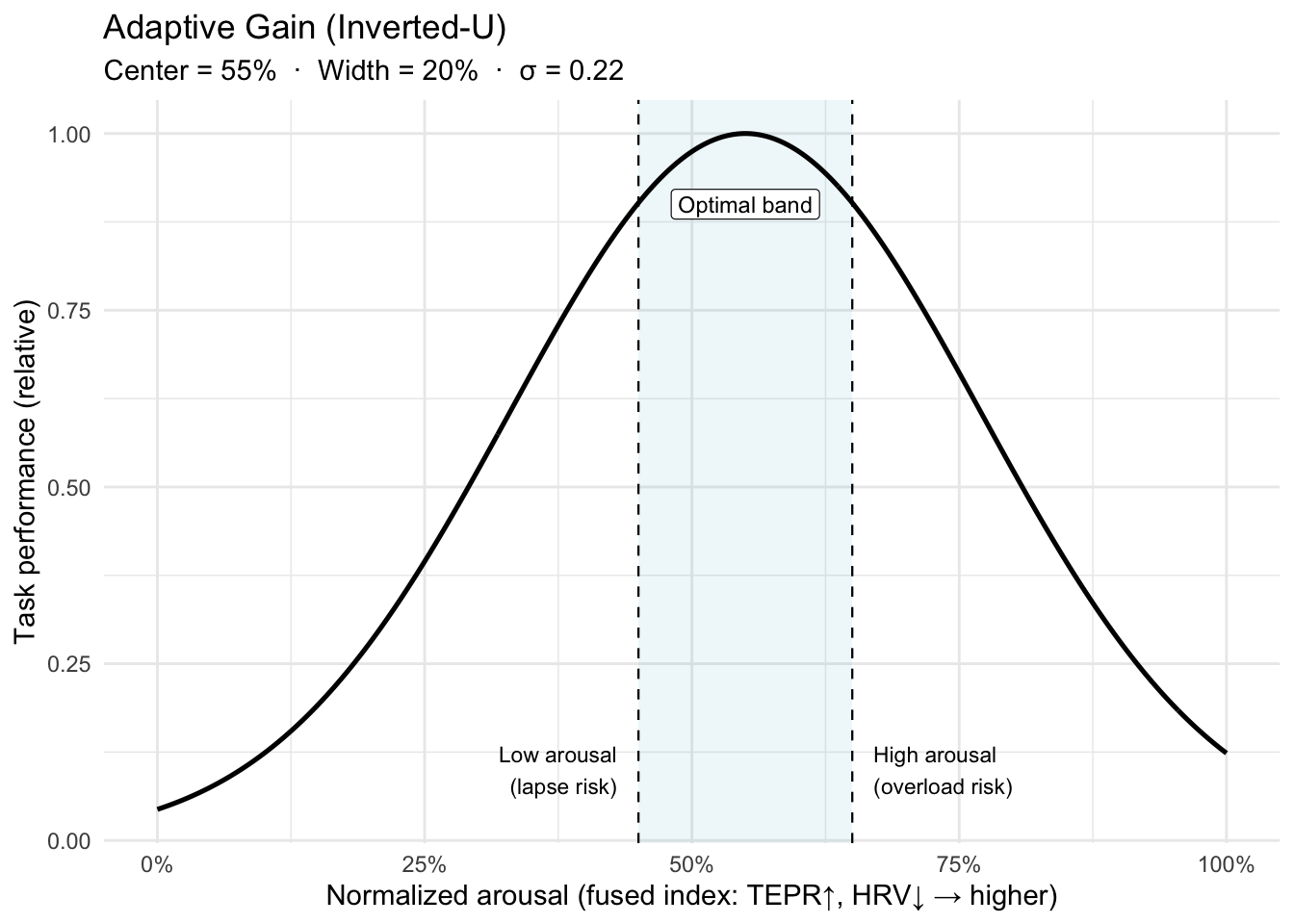
Threshold Policies: how they work
One problem, three lenses. Each policy below answers: what changes, when to use it, and how it maps to the production dashboard defaults.
X-axis detail: Normalized arousal = fused TEPR + HRV index ∈ [0,1].
Maps to Dashboard. The system fuses TEPR (↑) and HRV (↓) into a normalized arousal index ∈ [0,1]. Alerts fire when the index leaves the optimal band
[lo, hi].- Wider band → fewer alerts, gentler coaching.
- Narrower band → tighter coaching, higher nuisance risk.
- Hysteresis (small margins) is added to prevent alert “chatter” at band edges.
Notes for accuracy.
- The inverted-U is task- and person-dependent: expertise, stakes, and fatigue shift the peak (band_center) and width (band_width). That’s why calibration is per trainee.
- “Adaptive gain” is the mechanism (LC-NE modulating neural gain) that can yield this non-monotonic performance curve.
References. Yerkes–Dodson (1908); Aston-Jones & Cohen (2005, adaptive gain).
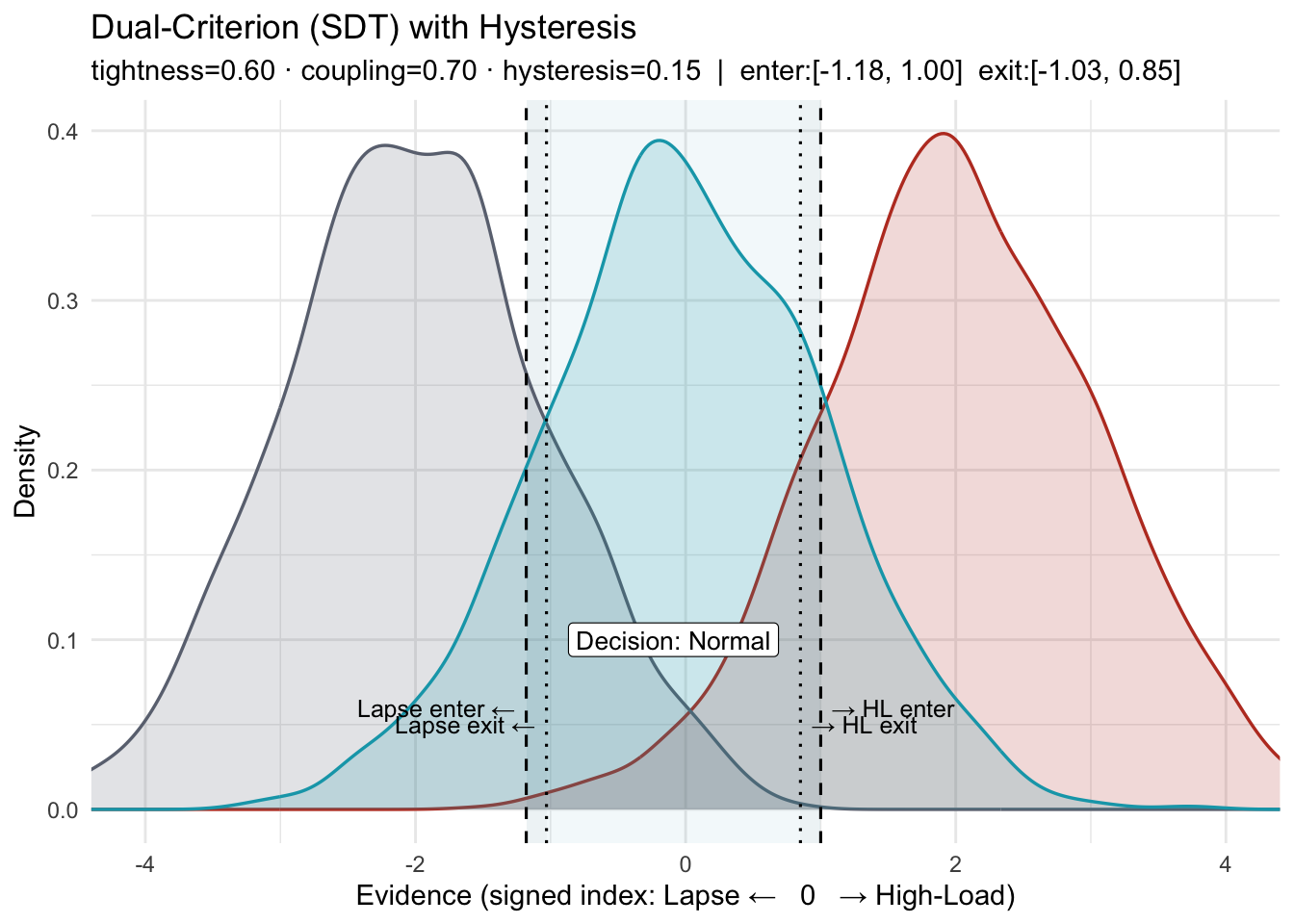
X-axis: a z-scored, signed evidence index from biosignals (e.g., TEPR↑, RMSSD↓). Higher → High-Load; lower → Lapse.
- What this shows. A three-state SDT layout (Lapse / Normal / High-Load) with two decision criteria and hysteresis (separate enter/exit thresholds).
criterion_tightnessnarrows or widens the Normal window by moving both criteria toward or away from 0.couplingcontrols symmetry: values < 1 move the Lapse boundary less than the High-Load boundary; values > 1 move it more.
- Why “Dual-Criterion,” not “Sensitivity.” In SDT, sensitivity is d′ (distribution separation). This policy adjusts decision criteria (bias), not d′.
How the two figures relate: The first figure defines the boundaries (enter/exit on each side). The second applies the same boundaries, nudged slightly if needed so at least one crossing is visible, to a noisy signal, showing how hysteresis prevents flip-flops near a boundary.
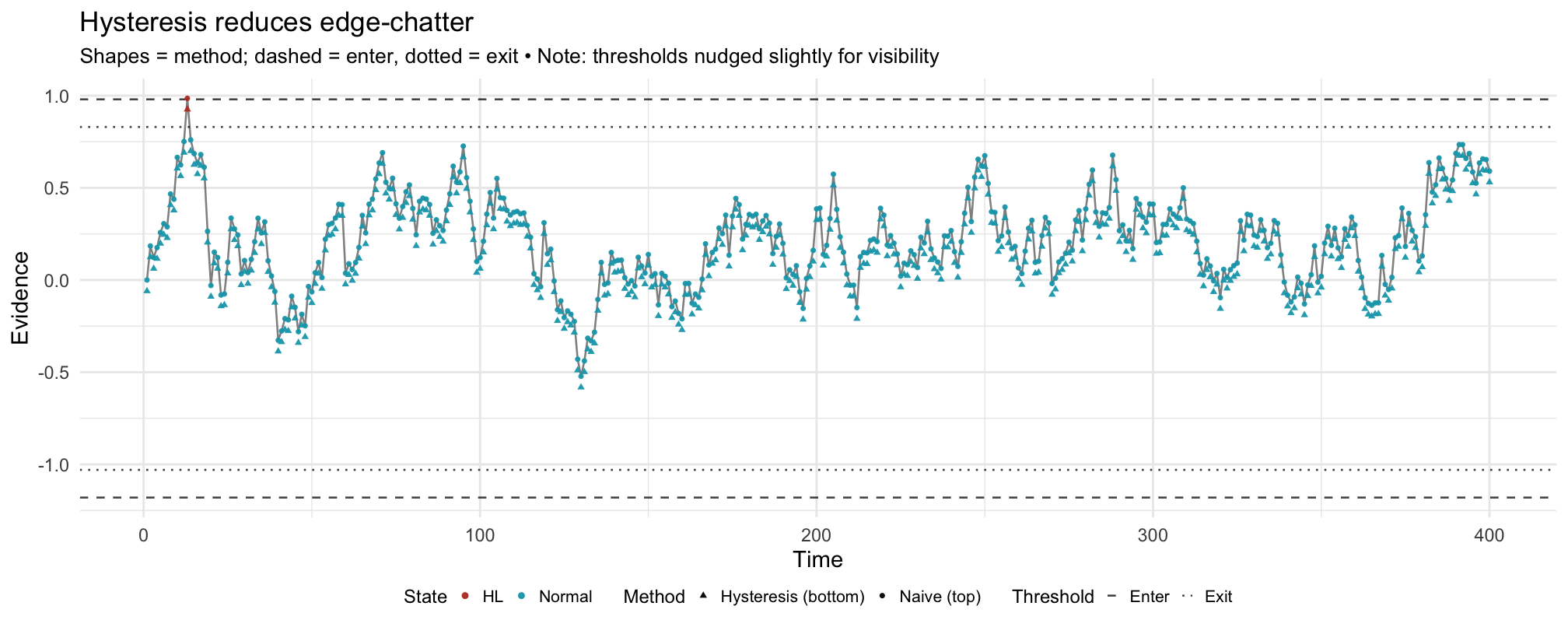
- Hysteresis. Enter/exit thresholds (and/or consecutive-sample confirmation) require persistent evidence to change state, reducing nuisance alerts.
- Maps to Dashboard. The control sets the HL and Lapse thresholds together. Alerts still require evidence + physiology (e.g., HL requires TEPR↑ or HRV↓; Lapse prefers low TEPR + blink anomalies).
- References. Macmillan & Creelman (Signal Detection Theory); NASA-TLX background (Hart & Staveland).
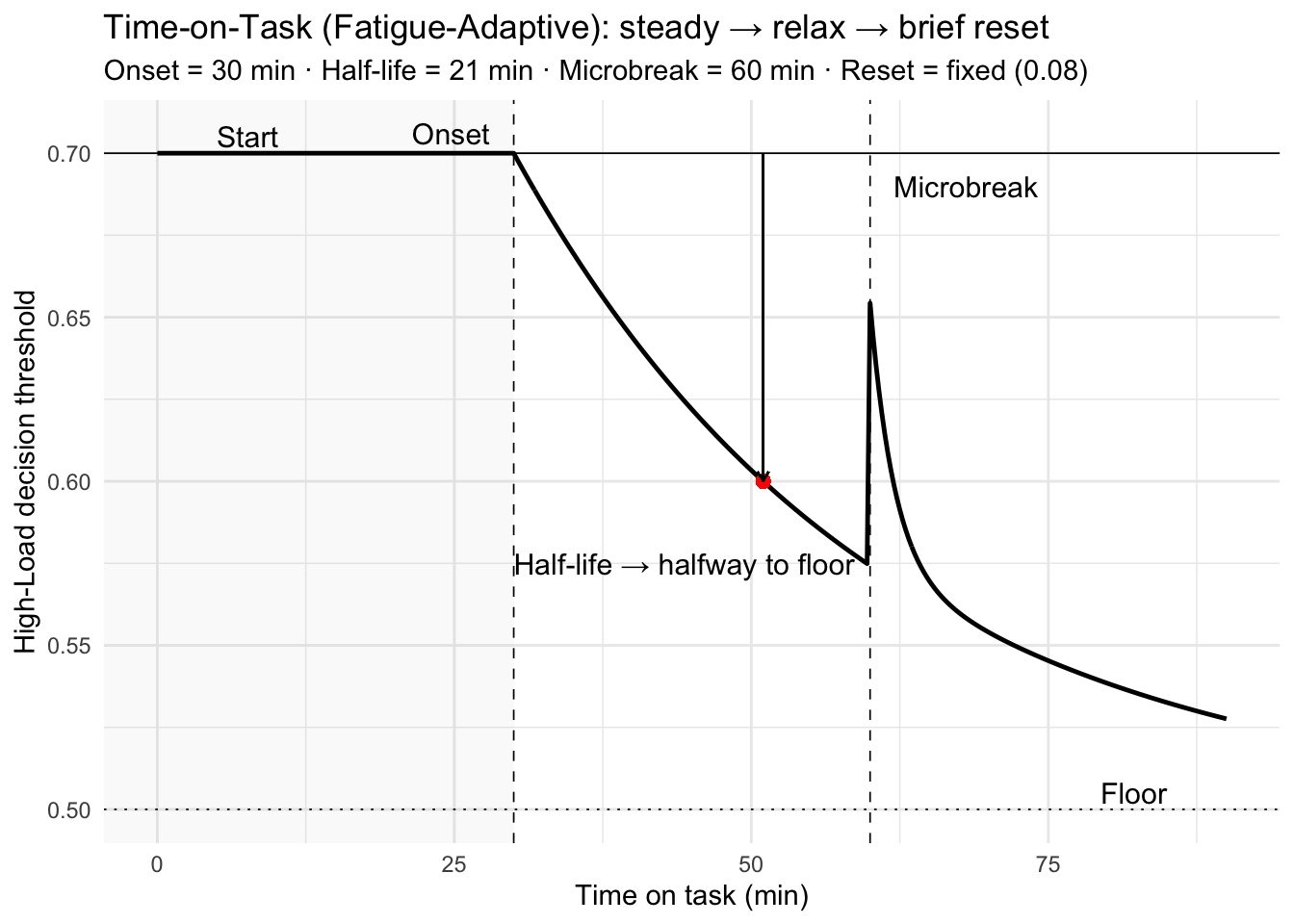
Note
How to read this policy
- Pre-onset (t < 30 min): the decision threshold stays at 0.70.
- Post-onset: the threshold relaxes exponentially toward the floor 0.50. In other words, the system becomes more tolerant of High-Load detections as vigilance degrades.
- Microbreak (t = 60 min): a small reset tightens the threshold, then decays over ~2 min. (Demo uses a fixed, modest reset.)
- Half-life: at t = onset + half-life = 30 + 21 = 51 min, the threshold sits halfway between 0.70 and 0.50.
- Design intent: this is a transparent, auditable controller on the criterion that is tunable per surgeon/task; it does not assume the evidence itself drifts.
Why a policy like this? Vigilance typically declines with time-on-task while perceived workload rises; brief microbreaks improve comfort and focus without harming flow. Pupil/HRV often show fast, partial recovery over 1–3 minutes. A time-scheduled, small criterion reset captures these operational realities without heavy modeling.
Good defaults (to be tuned):
onset_min20–30 min;fatigue_half_life_min15–30 min; reset proportional to observed pre/post microbreak recovery, with decay 1–3 min.References.
Warm, Parasuraman & Matthews (2008). Vigilance requires hard mental work and is stressful. Human Factors, 50(3), 433–441. DOI: 10.1518/001872008X312152
Dorion & Darveau (2013). Do micropauses prevent surgeon’s fatigue and loss of accuracy? Ann Surg, 257(2), 256–259. DOI: 10.1097/SLA.0b013e31825efe87
Park et al. (2017). Intraoperative “microbreaks” with exercises reduce surgeons’ musculoskeletal injuries. J Surg Res, 211, 24–31. DOI: 10.1016/j.jss.2016.11.017
Hallbeck et al. (2017). The impact of intraoperative microbreaks… Applied Ergonomics, 60, 334–341. DOI: 10.1016/j.apergo.2016.12.006
Luger et al. (2023). One-minute rest breaks mitigate healthcare worker stress. JMIR, 25, e44804. DOI: 10.2196/44804
Unsworth & Robison (2018). Tracking arousal with pupillometry. Cogn Affect Behav Neurosci, 18, 638–664. DOI: 10.3758/s13415-018-0604-8
Why thresholds must adapt
Interactive Training Lab
Compare all three threshold policies on the same biosignal stream. Switch policies mid-run, adjust parameters, and export configurations for production use.
Adaptive Gain
Dual-Criterion
Time-on-Task
Opens in new tab · May take a few seconds to load
Switch between policies on the same stream. Notice how the same physiologic trace produces different coaching behavior. Policy is a choice, and it should be teachable.
Production Dashboard
Live Monitor Overview
Component Details: Zoomable Gallery
Click any image to zoom and navigate with arrow keys.
ML Diagnostics Overview
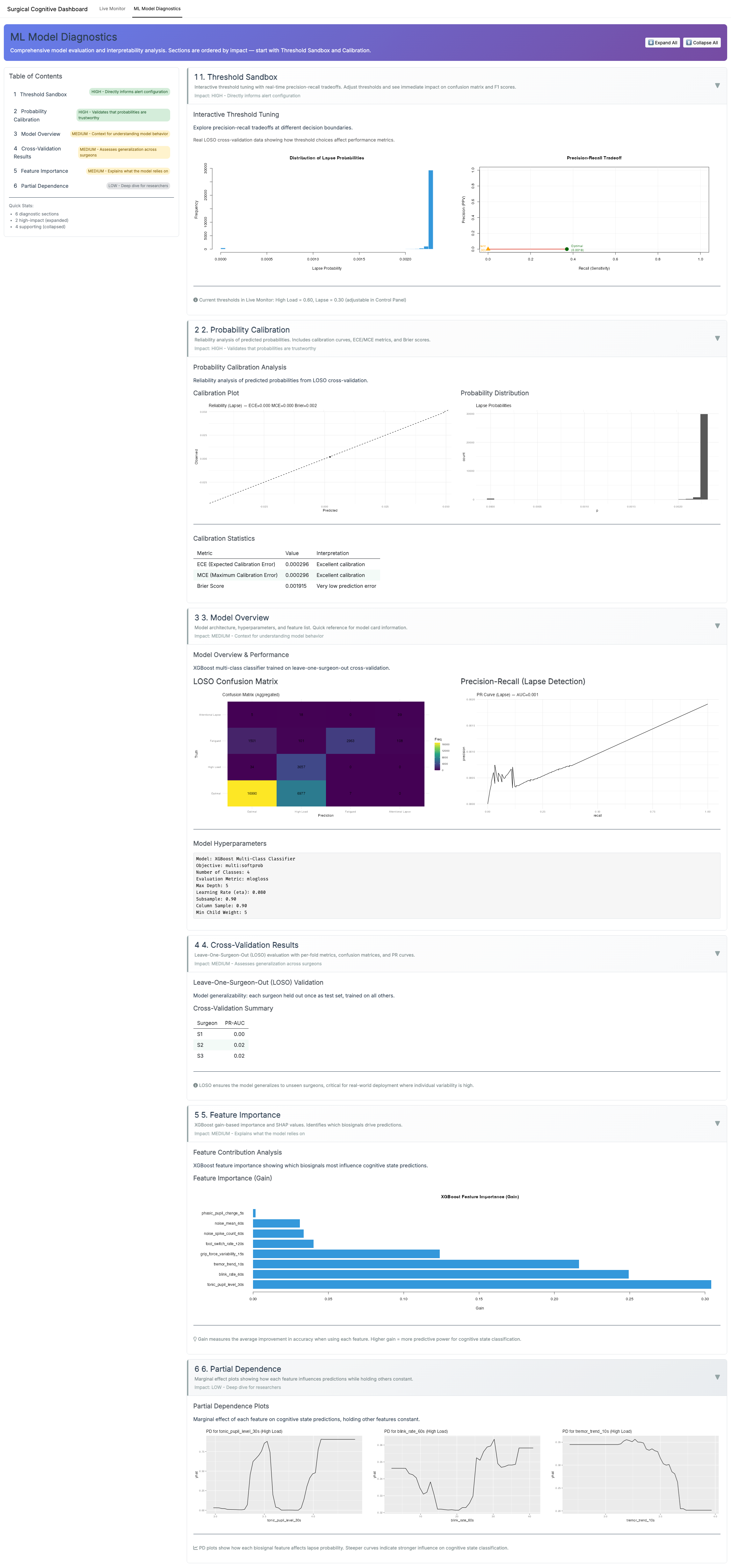
ML Diagnostics Details: Zoomable Gallery
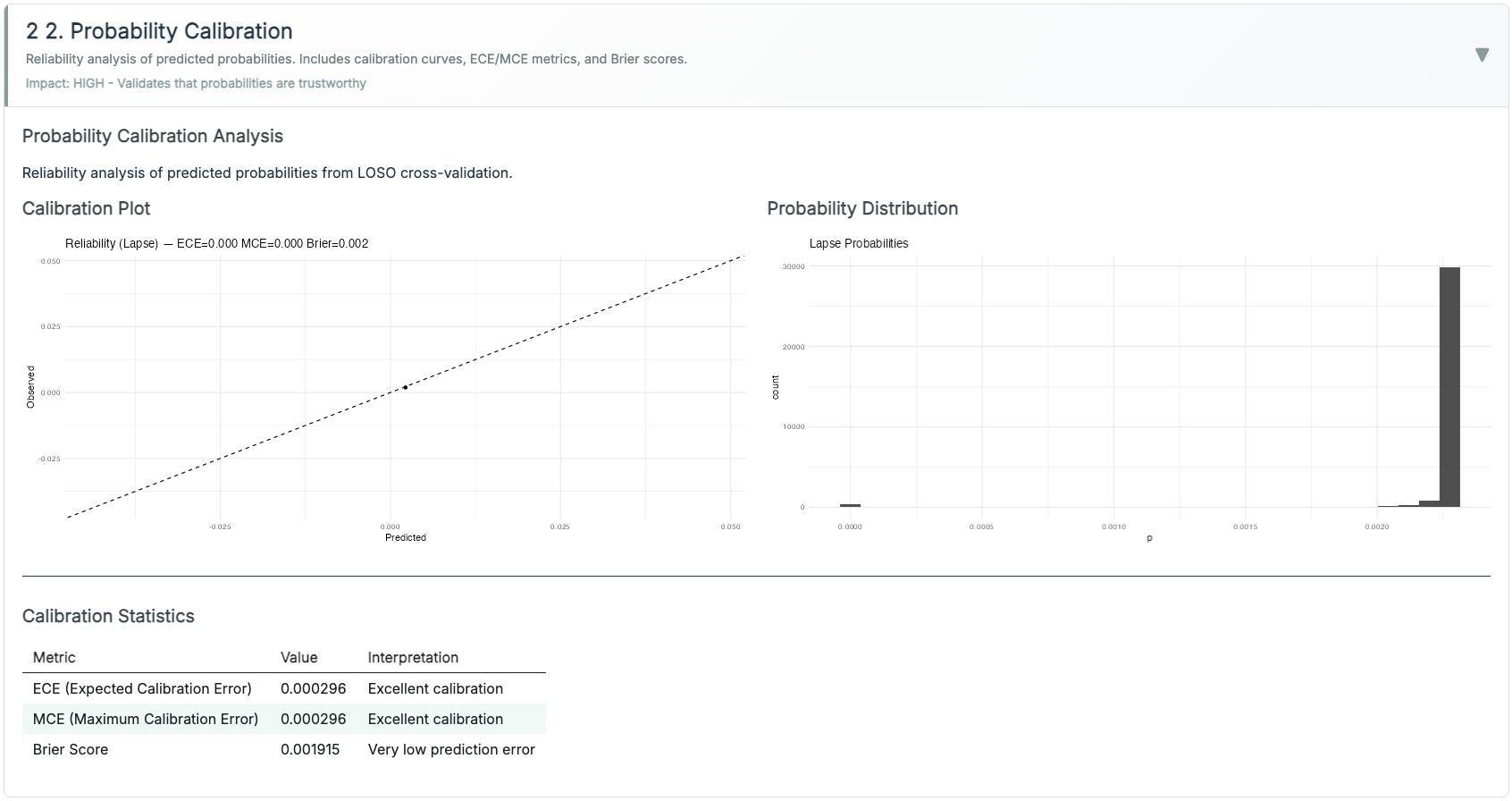
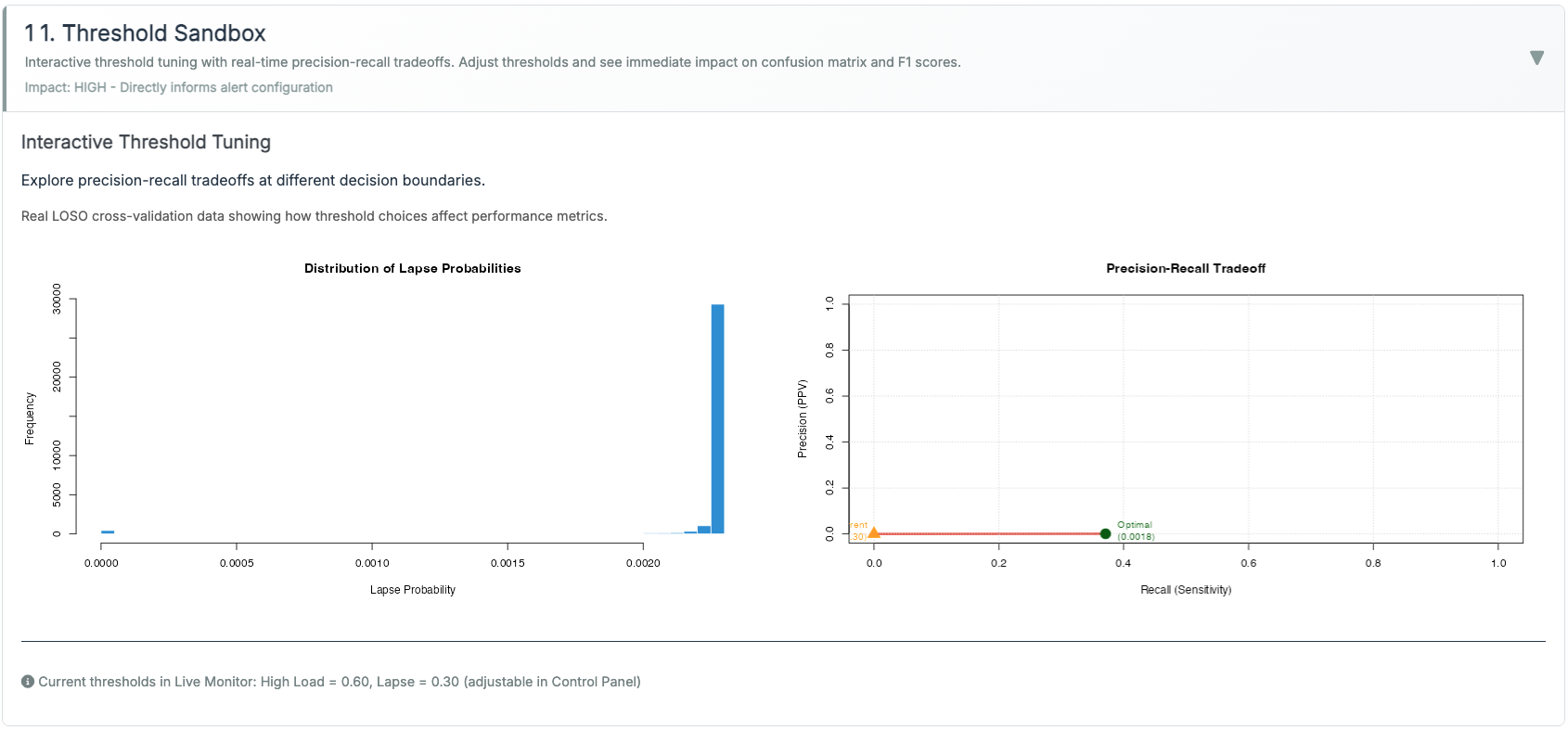
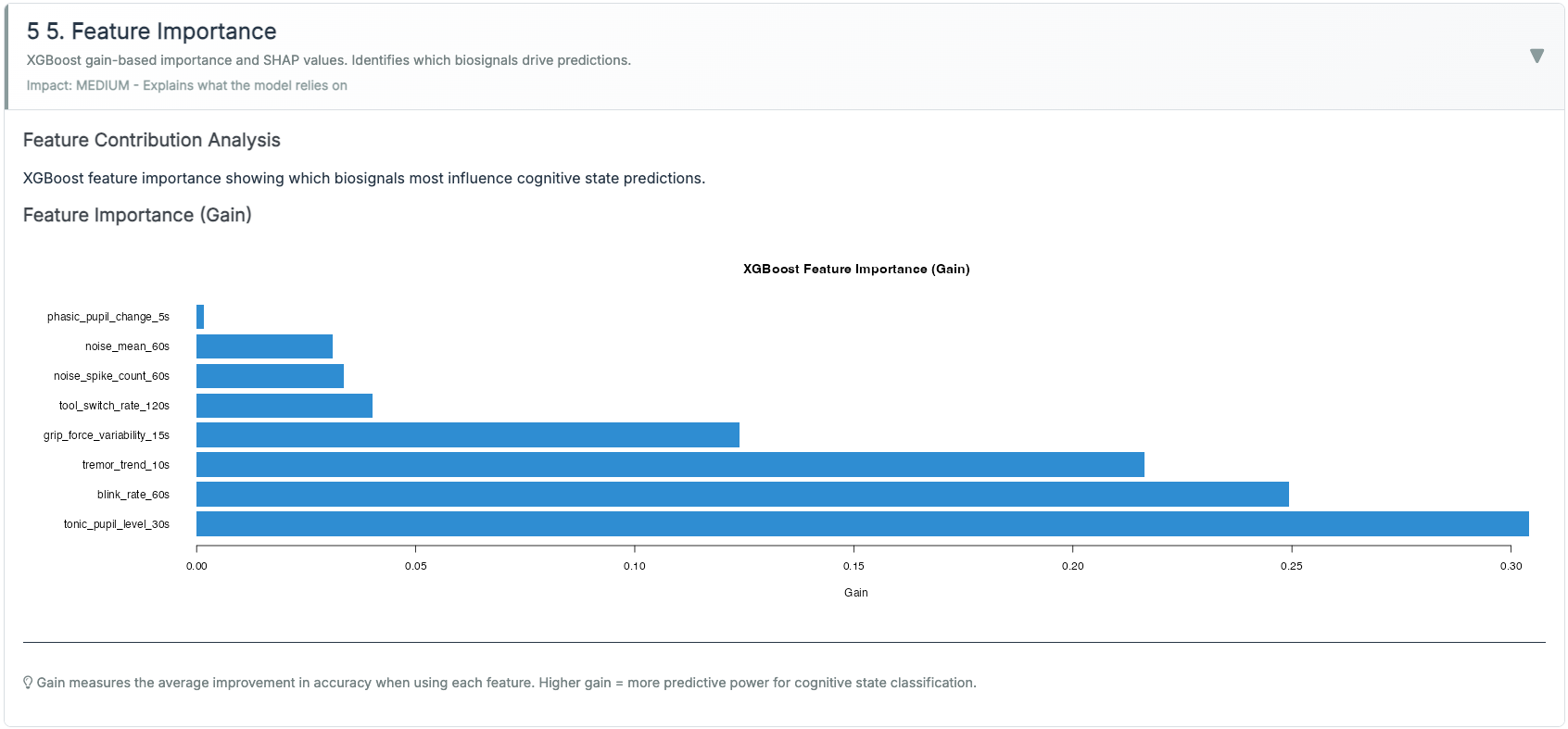
Methods (what runs under the hood)
Data & provenance.
I use (a) synthetic sessions produced by the same code paths as the live app (seeded; 10–30 min, 50–100 Hz raw) and (b) replayable demo logs exported from the dashboard. All analyses in this page use time-stamped streams (UTC, ms).
Signals & sampling.
Pupil diameter (mm; eye tracker), HRV from PPG/ECG (ms), grip force (N), tool-tip tremor (μm, 8–12 Hz band), blinks (blinks/min), ambient noise (dB). Signals are synchronized to a common clock and resampled to 10 Hz for feature windows.
Preprocessing.
- Pupil: blink interpolation → robust z-scoring within session; TEPR = event-locked delta (2–5 s).
- HRV: RMSSD computed over rolling 60 s (also 30/120 s for sensitivity); artifact correction via outlier trimming (5×MAD).
- Grip/tremor: 2–10 s rolling mean/SD; tremor via band-pass and RMS.
- Blink rate: rolling 60 s count; winsorized (1st/99th pct).
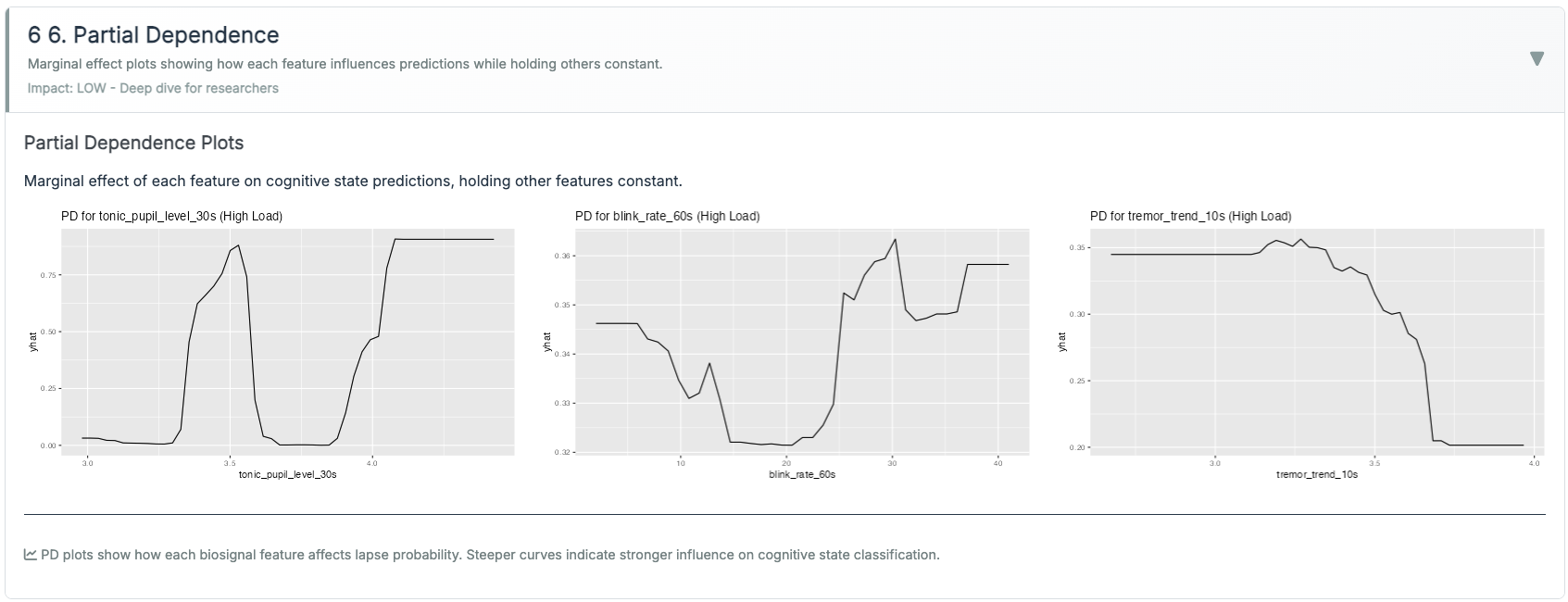
Features (examples; all z-scored within session).
- Pupil: tonic_30s_mean; tepr_5s_delta; pupil_cv_30s.
- HRV: rmssd_60s; rmssd_slope_60s; rmssd_ma_180s; rmssd×tepr interaction.
- Grip/Tremor: grip_mean_15s; grip_cv_15s; tremor_rms_10s; tremor_trend_60s.
- Ocular: blink_rate_60s; fixation_var_30s.
- Context: noise_db_30s.
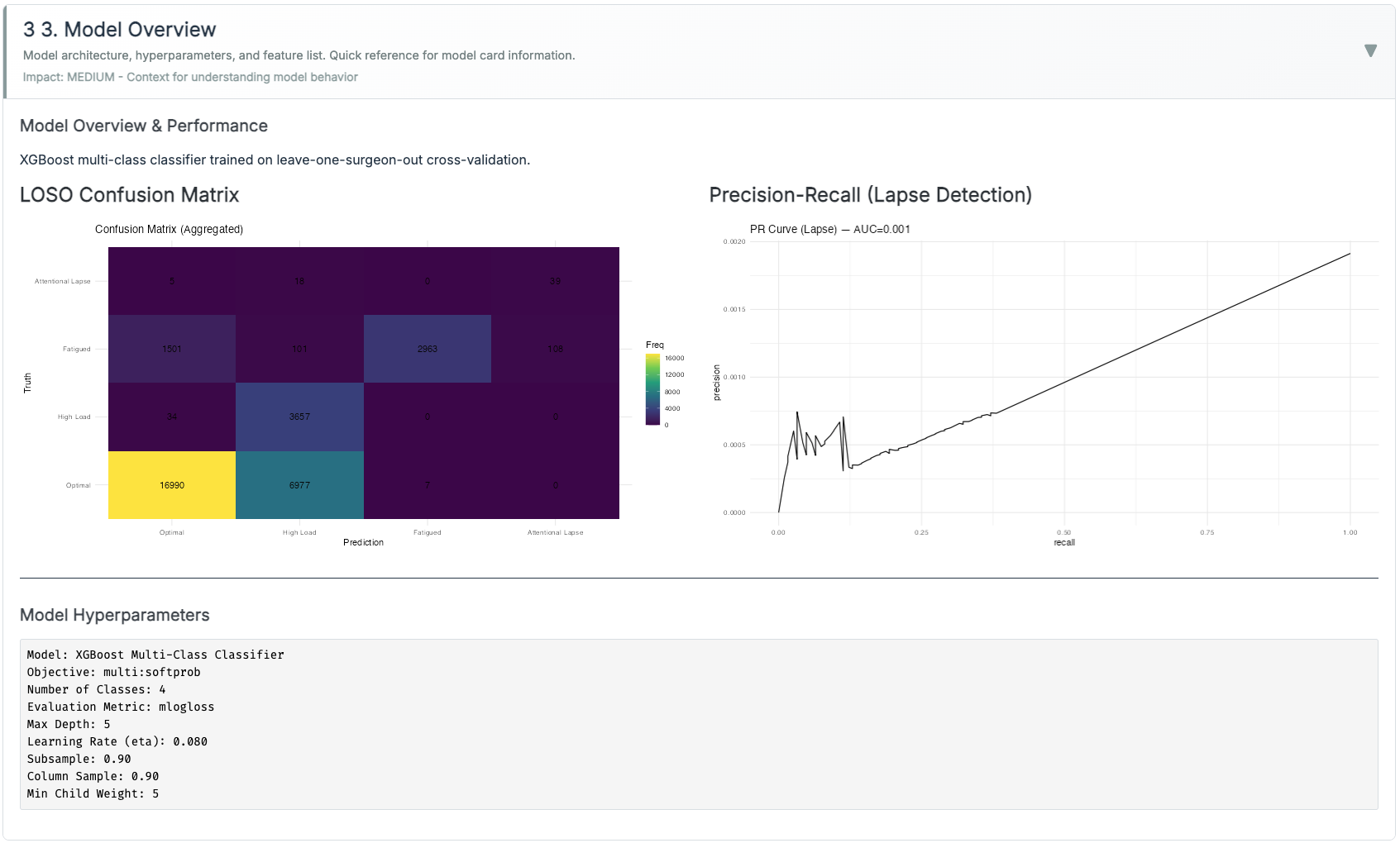
Modeling.
XGBoost (multi:softprob, 3 classes: Normal / High-Load / Lapse). Class imbalance handled via class weights (rare Lapse upweighted) and PR-AUC monitoring. Lapse probability is calibrated with Platt scaling (logistic on validation folds). I report ECE and Brier.
Threshold policies (runtime).
- Adaptive Gain (Inverted-U): keeps evidence within an optimal band.
- Dual-Criterion (SDT) with hysteresis: two criteria + enter/exit guards.
- Time-on-Task (Fatigue): hold → relax with half-life; microbreak gives a decaying reset.
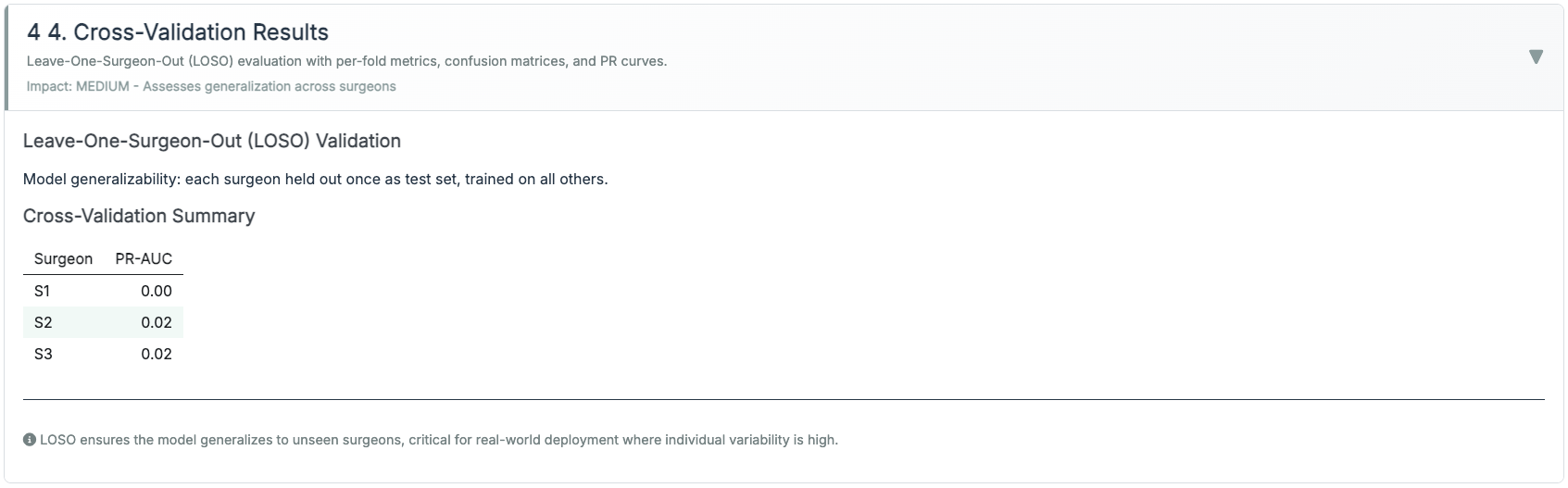
Validation.
Leave-One-Surgeon-Out (LOSO) where available; otherwise session-level 5× CV with subject leakage prevented. Hyperparameters chosen by Bayesian search, then frozen.
Reproducibility.
Seeds fixed; all plots are generated by scripts under scripts/90_make_gallery.R so the case study visuals match the live app implementation.
Methods & results that matter (ops KPIs)
I track outcomes that training leaders can act on:
- High-load minutes per hour (↓ is better). Target ≥20–30% reduction after policy tuning.
- Recovery latency after alerts/microbreaks (↓). Time for HRV/tremor to normalize; aim for <120 s median.
- Alarm burden & acceptance (↘ nuisance, ↗ adherence). Alerts/hour, % acknowledged, % acted upon.
- Stability (↗). Fewer state flips near thresholds with hysteresis vs naive criteria.
- Time-to-proficiency (↘). Sessions to hit competency rubric milestones.
What synthetic validation showed. Using held-out synthetic sessions (session-level 5-fold CV, subject leakage prevented), I found the XGBoost classifier distinguished Normal from High-Load with PR-AUC > 0.85; Lapse detection was weaker (PR-AUC ~0.65), reflecting its low prevalence (< 5% of time steps) and reliance on blink-burst patterns that are noisier in simulation than in real data. Platt-scaled probabilities had ECE < 0.06 on validation folds. I compared threshold policies on the same synthetic stream and confirmed that Adaptive Gain produced fewer nuisance alerts than a naive fixed threshold under the same biosignal trace, which was the intended behavior. I treat these results as proof-of-concept only; see Limitations for what they cannot establish.
Analytics: per-session trend lines + bootstrapped CIs; PR-AUC for Lapse, calibration error (ECE), and threshold-level lift curves for explainability.
Live clinical-style table with literature ranges
Limitations
Synthetic data only. All dashboard demonstrations and model evaluations use synthetic sessions generated by the same code paths as the live app. No real OR biosignal data has been collected or analyzed. Performance figures (e.g., cross-validation accuracy, calibration curves) reflect behavior on simulated data and may not generalize to real surgical environments.
No prospective pilot. The system has not been tested with real surgical trainees. Threshold defaults, coaching heuristics, and alert timing are grounded in published literature but are unvalidated in the target context. A prospective pilot, even with N=5–10 trainees across two or three sessions, would be needed before drawing any conclusions about training efficacy.
Gaze-based pupillometry requires hardware not present here. The dashboard assumes a table-mounted or console-integrated eye tracker (e.g., EyeLink or Tobii integration) as the pupil signal source. No such hardware was used in building or testing this proof-of-concept. Signal quality, blink rate, and TEPR estimates in real OR conditions will differ from the synthetic proxy used here.
Cognitive state labels are proxies. The XGBoost classifier predicts Normal / High-Load / Lapse based on physiological features. These labels are theoretically motivated but not validated against independent ground-truth measures of cognitive state (e.g., concurrent performance data, subjective workload ratings collected during the same sessions).
Single-rater design, no inter-rater validation. All system design decisions, including threshold policies, feature definitions, and alert criteria, were made by a single researcher. Independent expert review of the threshold logic and coaching heuristics has not been conducted.
Product vs. Lab: how they fit
The Lab teaches the concepts and lets instructors tune policy; the Dashboard runs that policy live with guardrails and explains why an alert fired.
| Product vs. Lab: how they fit | ||
| Operational app (left) vs. pedagogy sandbox (right) | ||
| Aspect | Production Dashboard | Training Lab |
|---|---|---|
| Purpose | Real-time monitoring & decision support | Theory exploration & threshold policy tuning |
| Audience | Clinicians, safety officers | Educators, researchers |
| Features | Live gt table, tuned alerts, evidence fusion (pupil + HRV + grip/tremor) | Three paradigms (Adaptive Gain, SDT+hysteresis, Time-on-Task) |
| Latency | < 1 s UI; heavier data load | Instant |
| Interactivity | Threshold policies runnable; microbreak logging | Side-by-side policy comparisons; sliders |
| Calibration | XGBoost + Platt scaling; reliability curve (ECE/Brier) | Not model-based; exports policy defaults |
| Status | Stable, no extra wearables UI | Experimental, fast iteration |
| Note. The Lab defines pedagogy & defaults; the Dashboard executes with calibrated probabilities and alert hygiene. | ||
From SST to the OR: what transferred
Alert load determines adoption, not accuracy. At SST I saw analysts disable alerts not because the model was wrong, but because the alert rate was too high to act on. This dashboard targets ≤0.6 alerts/min and tracks nuisance rate as a first-class metric.
Rationale must travel with the alert. An alert that says “High-Load confirmed: TEPR↑ + RMSSD↓” is actionable. An alert that says “state: 2” is not. Every alert in the dashboard displays the physiological evidence that triggered it.
Setup friction is a clinical constraint, not a preference. Every added cable, cap, or calibration step reduces the chance of consistent use in a training program. The zero-headgear, sub-60-second-setup constraint came directly from observing how quickly OR teams abandon tools that interrupt workflow.
Deployment & Privacy
Runs as a Docker image or on ShinyApps; can embed in training portals with a single <iframe>. By default, surgeon biometrics are ephemeral: the system retains only de-identified aggregates (for QA/research) with explicit consent. The system is assistive, not autonomous. The clinician remains in the loop, with visible rationale for alerts.
What’s next: tailored pedagogy
- Estimate the trainee’s arousal band. Use early sessions to fit a simple sweet-spot width (from TEPR/HRV vs performance), then personalize alert sensitivity.
- Phase-aware coaching. Different thresholds for docking, dissection, suturing; tighten only where error costs are high.
- Post-hoc debriefs. Auto-compile moments of sustained overload (≥30 s) with linked video, instructor notes, and the coaching action taken.
- Prospective classroom studies. Randomize microbreak timing/pacing advice and measure effects on recovery latency and learning curves.
What this is: A proof-of-concept training aid that fuses biosignals with robot telemetry to surface when coaching is most needed. Designed for surgical education contexts, not clinical diagnosis.
What this is not: A medical device, a certification tool, or a validated clinical system. It does not replace instructor judgment and has not been tested with real OR data. See Limitations.